在 Day20 淬鍊之章-多檔案上傳 ETL 流程-設計篇 中,我們探討了三種多檔案上傳控制的解法:
而對於本系列的 Anime Lakehouse 專案 而言:
animes, ratings)因此,本篇將採用 EventBridge 定時檢查 的設計,透過每日自動化排程來檢查 S3 檔案狀態,並在資料齊全後自動啟動 Glue Workflow。
整體架構流程如下: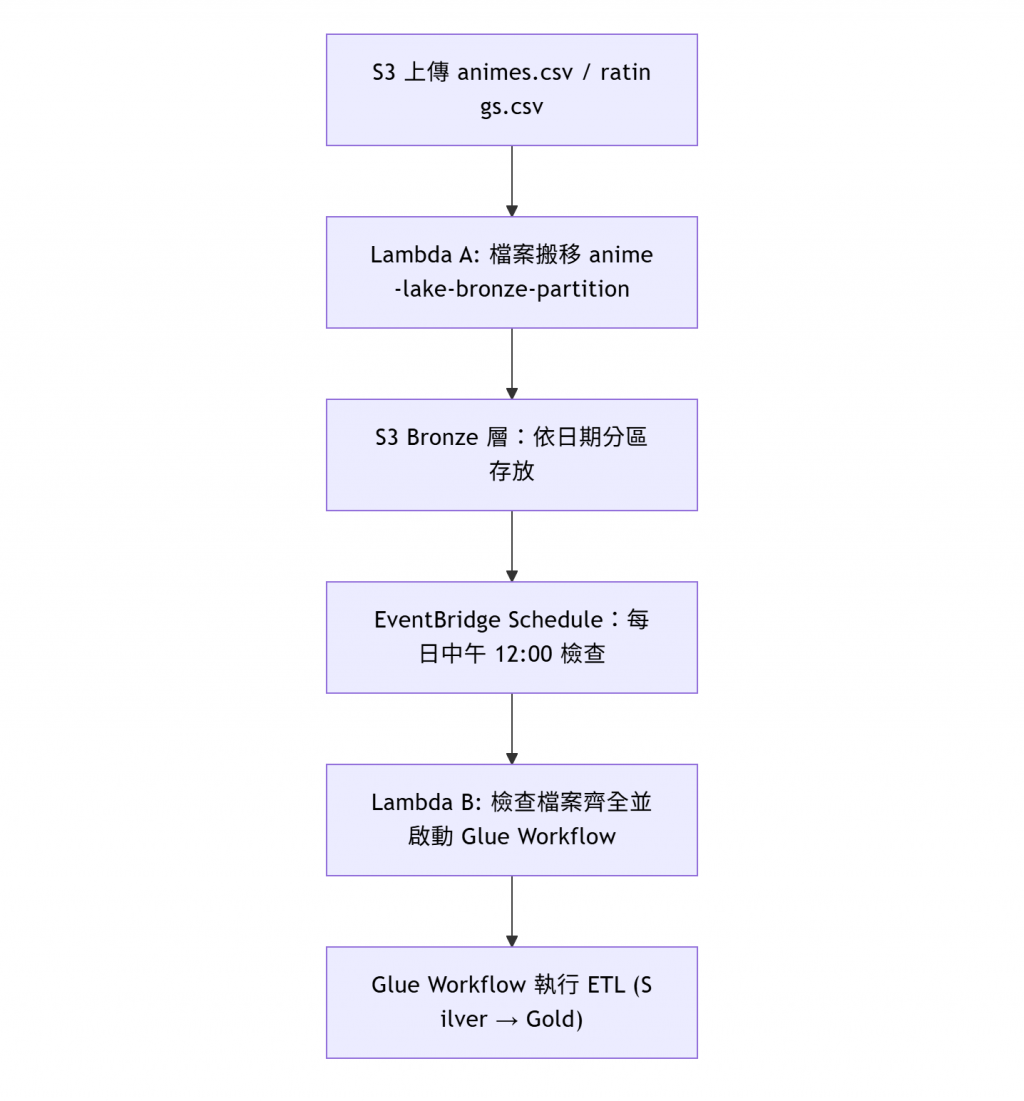
在先前的章節中,我們的 Lambda (anime-lake-bronze-partition)
同時負責兩件事:
這樣的設計雖然能運作,但在流程變得複雜後,會使得維護與除錯變得困難。
因此,從本篇開始,我們將 Lambda 拆分為兩支職責明確的函式,分別處理「檔案整理」與「Workflow 觸發」。
| Lambda 名稱 | 功能定位 | 觸發方式 | 主要任務 | 說明 |
|---|---|---|---|---|
| 🟤 anime-lake-bronze-partition | Bronze 層檔案整理 | S3 EventBridge (即時觸發) | - 接收上傳事件- 解析檔名日期- 搬移檔案到分區目錄 | 每次上傳時即時歸檔 |
| 🟣 check_files_and_trigger_workflow | 檔案檢查與 Workflow 啟動 | EventBridge Schedule (每日排程) | - 檢查檔案是否齊全- 若齊全則呼叫 Glue Workflow | 每日固定時間啟動 ETL |
未來若新增 dataset(如 users.csv),只需調整檢查 Lambda 的邏輯即可,Bronze Lambda 無須改動。
check_files_and_trigger_workflow
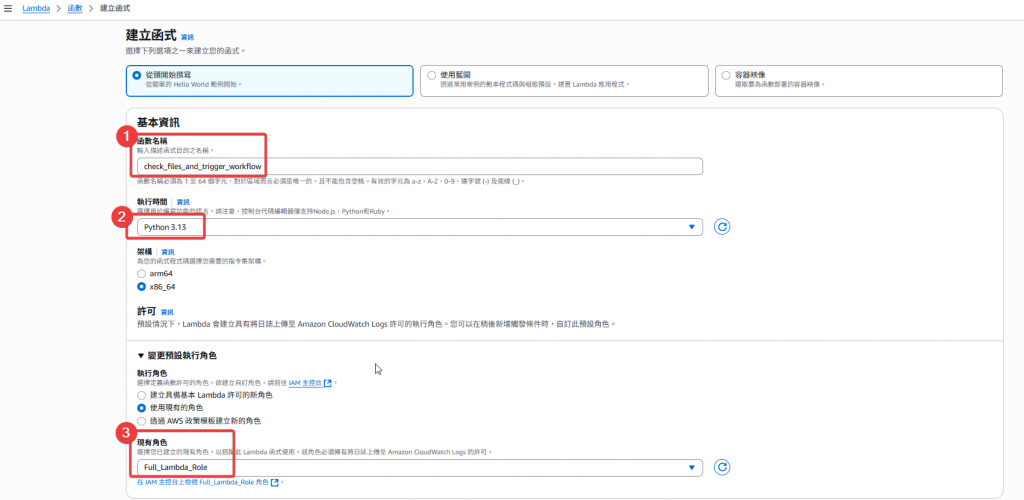
animes.csv 與 ratings.csv 是否皆存在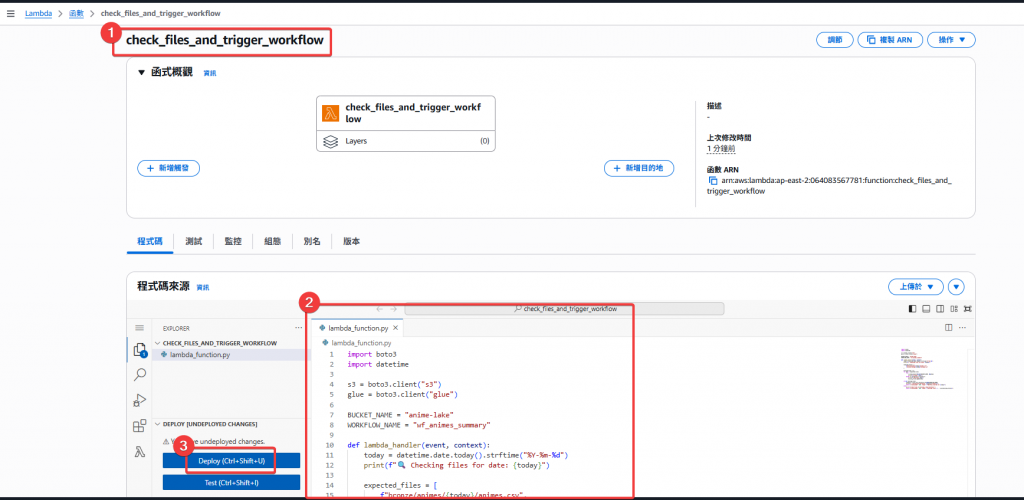
import boto3
import datetime
s3 = boto3.client("s3")
glue = boto3.client("glue")
BUCKET_NAME = "anime-lake"
WORKFLOW_NAME = "wf_animes_summary"
def lambda_handler(event, context):
today = datetime.date.today().strftime("%Y-%m-%d")
print(f"🔍 Checking files for date: {today}")
expected_files = [
f"Bronze/animes/{today}/animes.csv",
f"Bronze/ratings/{today}/ratings.csv"
]
missing_files = []
for key in expected_files:
try:
s3.head_object(Bucket=BUCKET_NAME, Key=key)
print(f"✅ Found: {key}")
except s3.exceptions.ClientError:
print(f"❌ Missing: {key}")
missing_files.append(key)
if not missing_files:
response = glue.start_workflow_run(Name=WORKFLOW_NAME)
print(f"🚀 Started Glue Workflow: {response['RunId']}")
return {"statusCode": 200, "body": f"Workflow started for {today}"}
else:
print("⏳ Some files are missing, skip execution.")
return {"statusCode": 200, "body": f"Missing files: {', '.join(missing_files)}"}
Step1:首先先切換到使用者 Joe,我們需要對 DE Group 新增可以建立 EventBridge 排程的 Policy
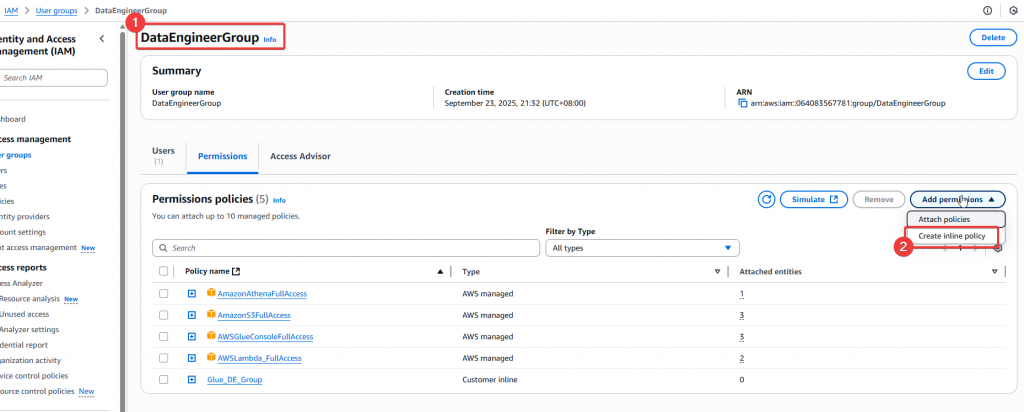
Step2:接著需要建立一個自定義 Policy AnimeLake_Scheduler_FullAccess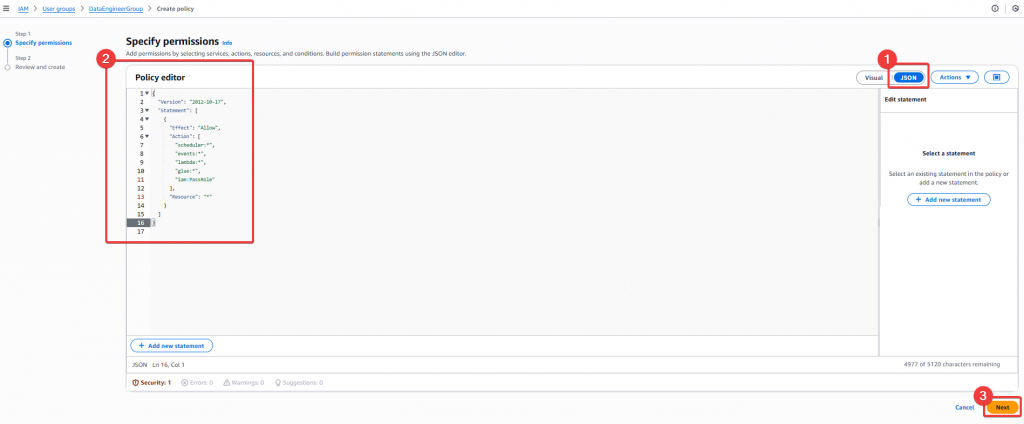
Policy Json:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"scheduler:*",
"events:*",
"lambda:*",
"glue:*",
"iam:PassRole"
],
"Resource": "*"
}
]
}
Step3:然後確認 Policy 無誤後,就可以點選 「Create Policy」
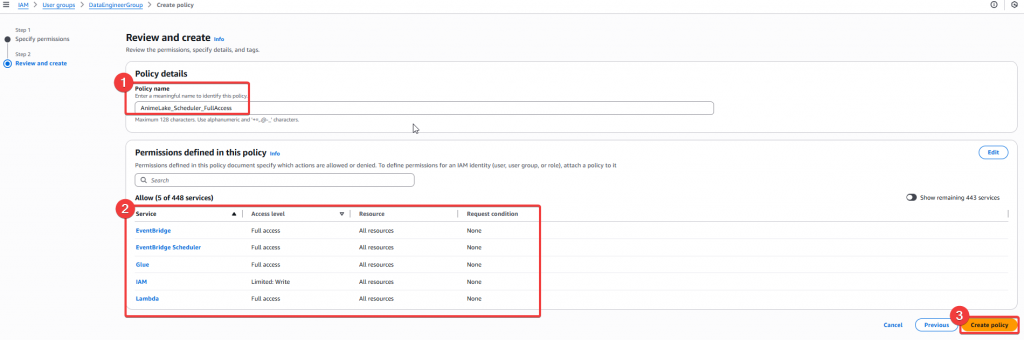
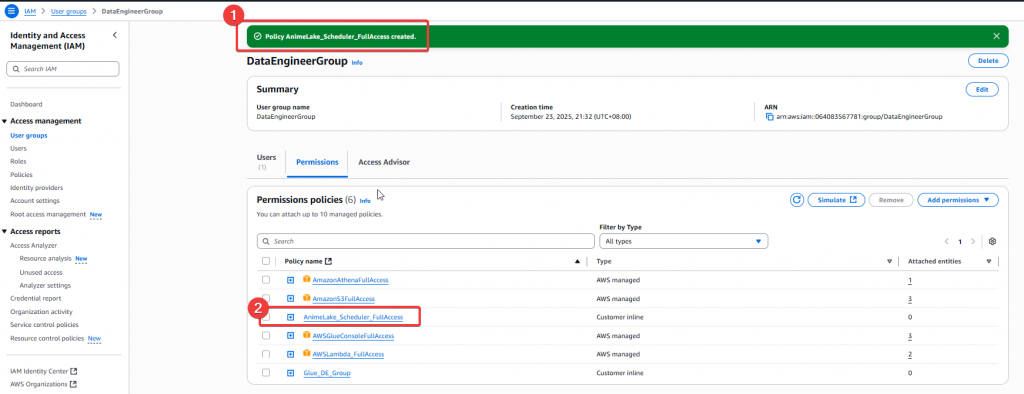
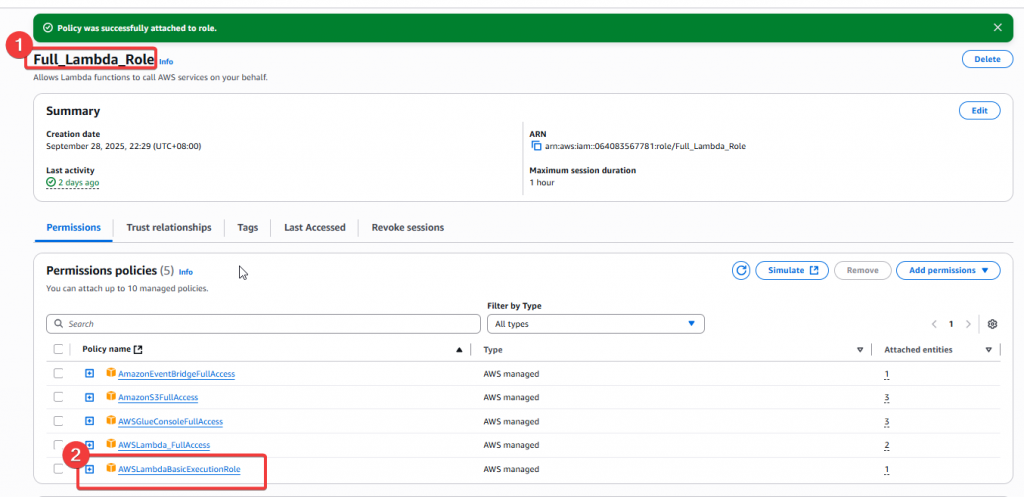
Step4:給予 DE Group Policy 後,我們至 IAM Role 找到 Full_Lambda_Role 角色,要賦予該 Role 使用 EventBridge 的權限
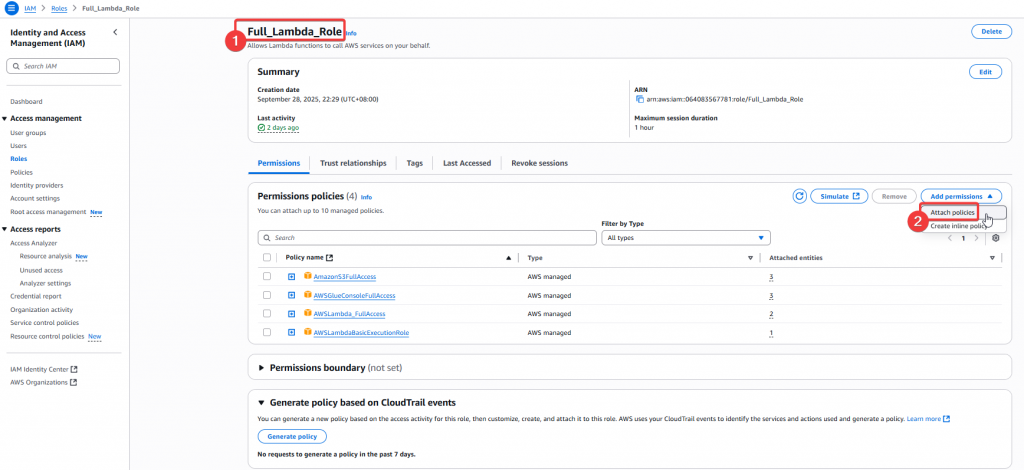
Step5:我們這次要新增AmazonEventBridgeFullAccess,這樣就可以用此 Role 來操作 EventBridge
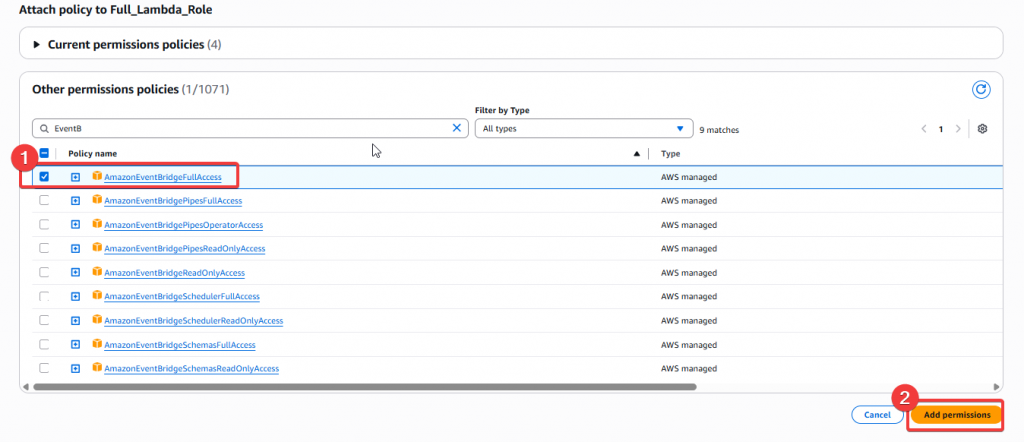
Step6:接著我們還需要將 scheduler 的服務允許加到 Full_Lambda_Role 角色的 「Trust relationships」清單內
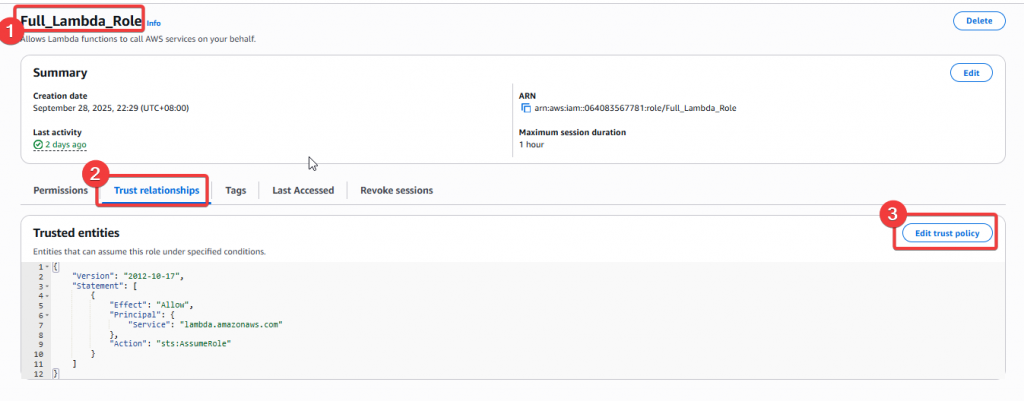
Step7:將 trust policy 貼入下方 Json 區塊內,接著點選「Update Policy」按鈕
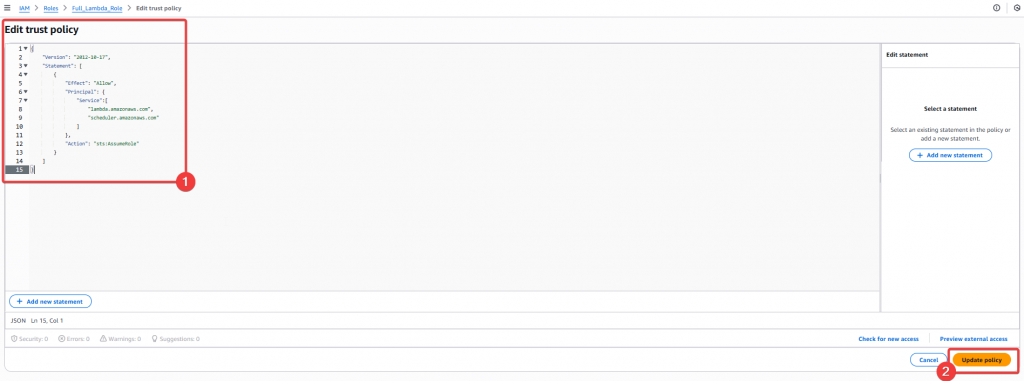
Policy Json:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"lambda.amazonaws.com",
"scheduler.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
Step8:最後來確認是否有成功建立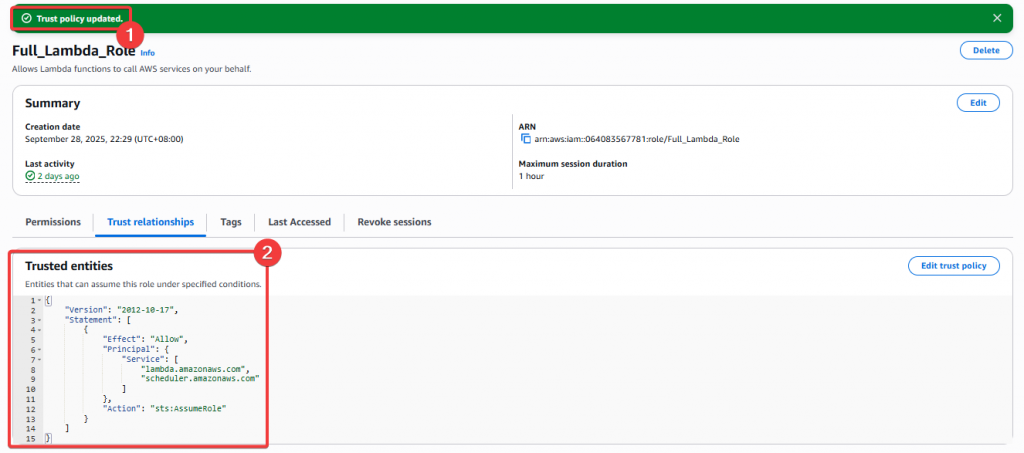
經過以上設定後,即可以透過使用者
Andy搭配Full_Lambda_Role角色建立 EventBridge 排程。
Step1:找到 EventBridge 服務後,點選建立 EventBridge 排程的選項,並點選「建立排程」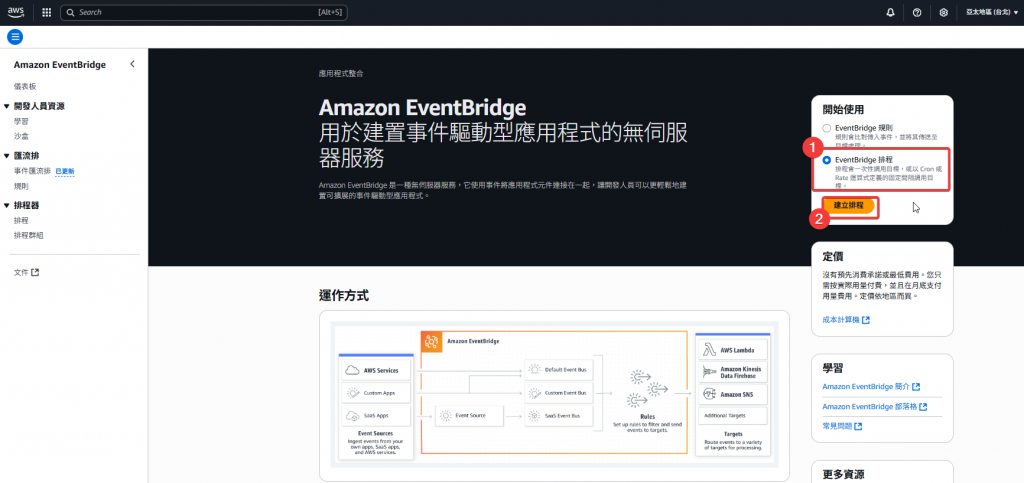
Step2:建立排程
tr_anime_files (可自行調整)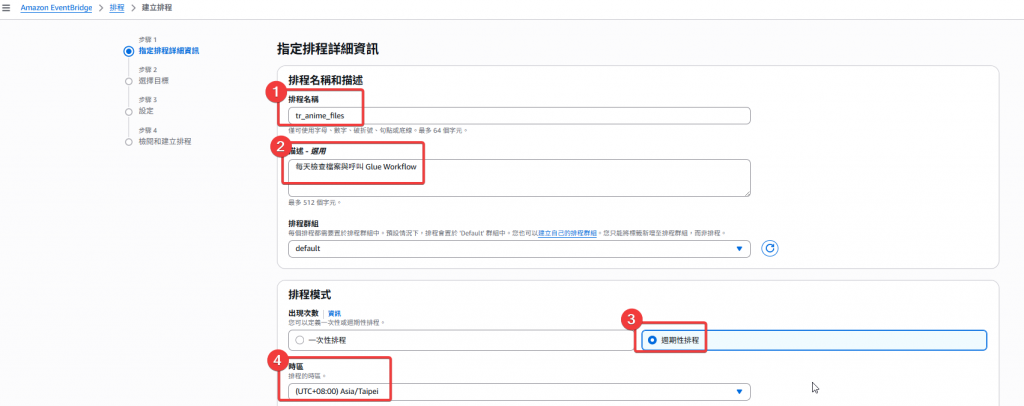
Step3:設定排程時間
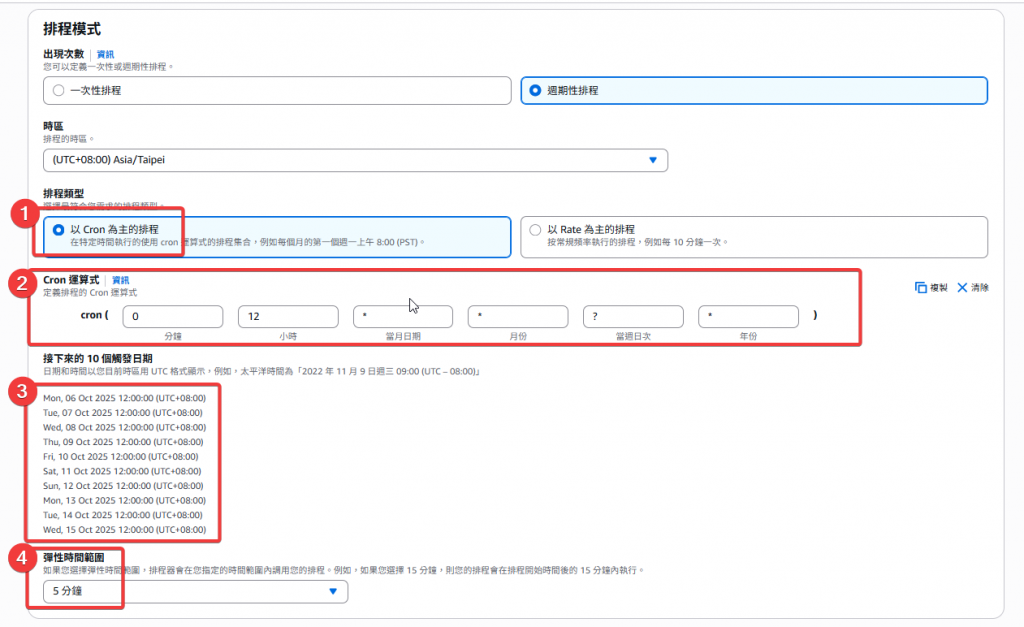
Cron 運算式:
cron(0 12 * * ? *)
Step4:選擇目標服務
check_files_and_trigger_workflow
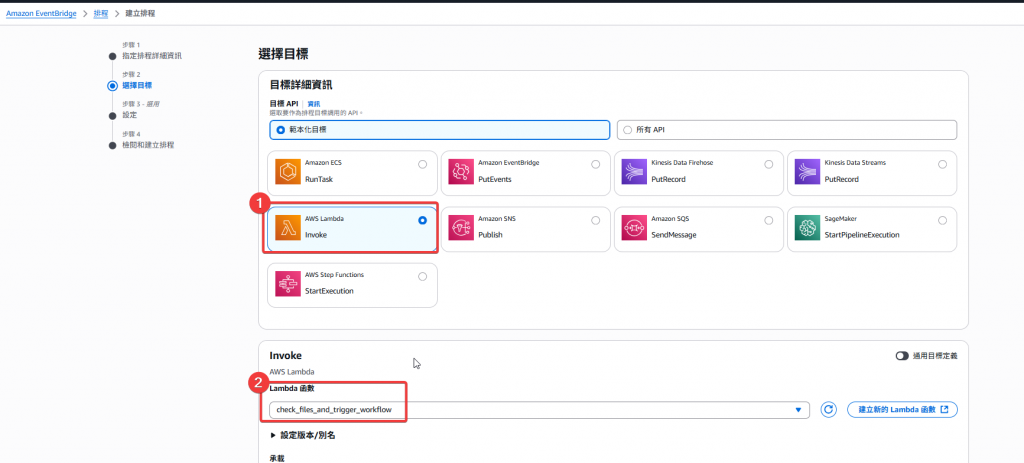
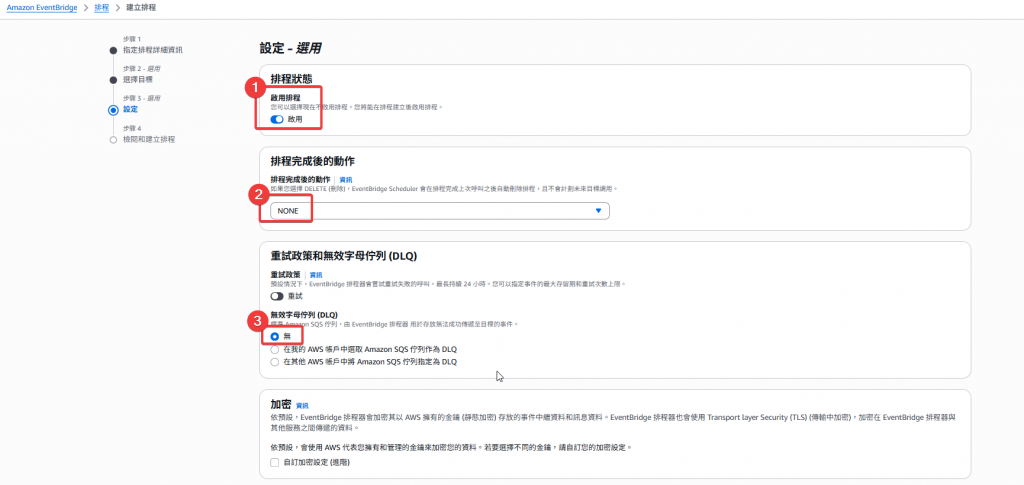
Step5:確認排程其餘設定
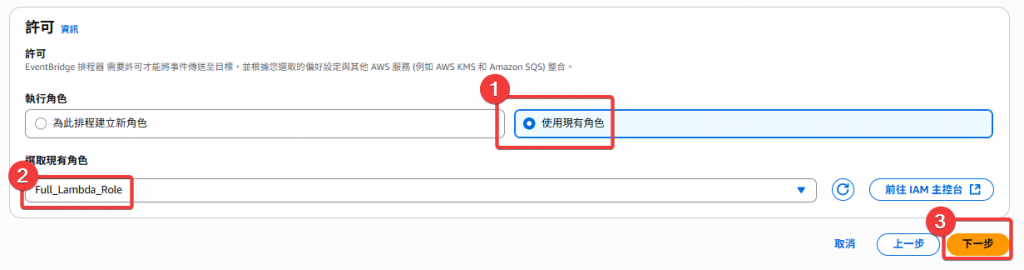
Step6:選擇執行 Role Full_Lambda_Role
Step7:最後的檢閱,看看設定上有無錯誤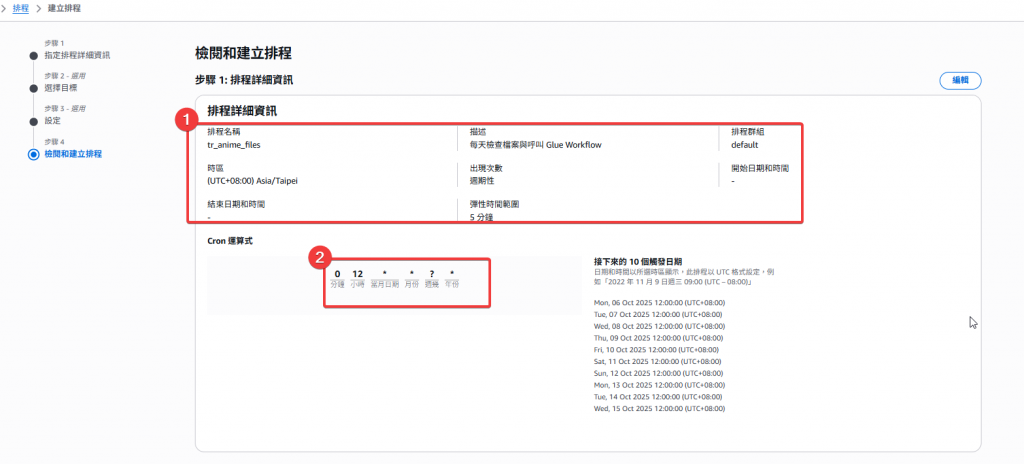
Step8:確認排程建立完畢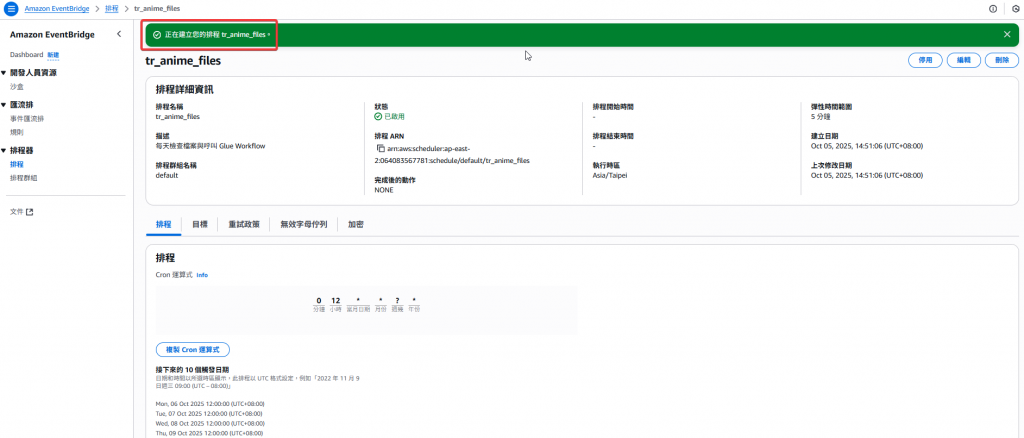
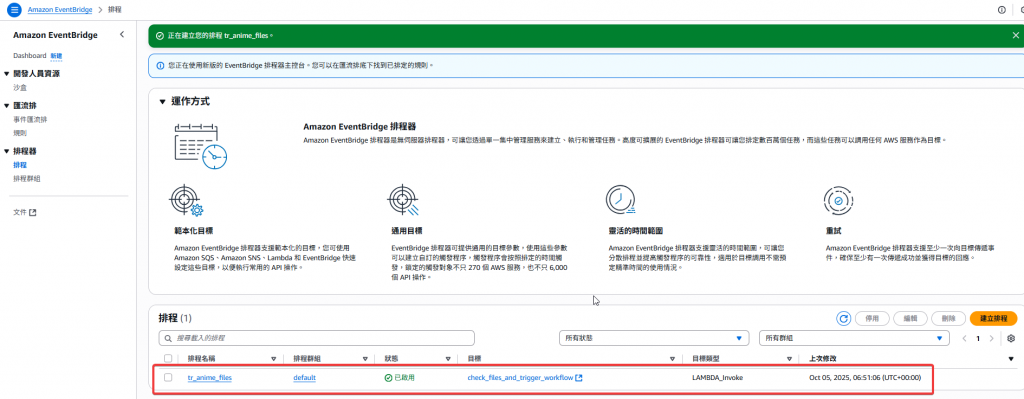
經過以上設定後,即完成定時的排程設定,當每天中午 12:00 時,該排程將會於五分鐘內執行 Lambda:check_files_and_trigger_workflow。
import boto3
import os
import re
s3 = boto3.client("s3")
def lambda_handler(event, context):
record = event["Records"][0]
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
# 檔名 (不含路徑)
filename = os.path.basename(key)
# 正則解析 dataset 與日期 (YYYYMMDD)
match = re.match(r"^(animes|ratings)_(\d{8})\.csv$", filename)
if not match:
return {
"statusCode": 400,
"body": f"Unsupported file format: {filename}"
}
dataset, file_date_raw = match.groups()
file_date = f"{file_date_raw[0:4]}-{file_date_raw[4:6]}-{file_date_raw[6:8]}"
# 生成新 S3 路徑
new_key = f"Bronze/{dataset}/{file_date}/{dataset}.csv"
# 搬移檔案
s3.copy_object(
Bucket=bucket,
CopySource={"Bucket": bucket, "Key": key},
Key=new_key
)
s3.delete_object(Bucket=bucket, Key=key)
return {
"statusCode": 200,
"body": f"File {filename} moved to {new_key}"
}
透過將 Lambda 拆分為兩支,我們成功建立出穩定又自動化的多檔案 ETL 流程:
✅ 模組化設計: 不同階段的邏輯分離,維護性更高。
✅ 穩定性提升: 錯誤可追溯、監控容易。
✅ 彈性可調整: 可自由設定檢查頻率與執行時間。
下篇我們皆透過 「Day22 淬鍊之章-多檔案上傳 ETL 流程-實作篇2」來實際確認排程的運作狀況,以及設定「排程通知」。
[1] Amazon EventBridge Scheduler
[2] Using AWS Lambda with Amazon S3
[3] AWS Lambda IAM 權限設定


 iThome鐵人賽
iThome鐵人賽